Heron can be deployed on different environments such as Mesos, Yarn and Slurm. In this post we will explore how to deploy Heron in Mesos with Apache Aurora. Apache Aurora is a services manager on top of Apache Mesos. It can spawn and run long running applications such as servers, on a set of machines managed by Mesos and keep them running (restart them if they failed etc) until they are being stopped.
Heron uses Apache ZooKeeper as a state manager. In this post we'll explore how to setup Aurora on three Ubuntu 14.04 machines and run a Mesos cluster on these machines to deploy Heron. To distribute the files across the cluster we'll use the HDFS. So we need to install HDFS on the machines as well.
Here are the steps we will explore in this post
- Deploy Apache Mesos & Apache Aurora on three Ubuntu 14.04 machines
- Install HDFS
- Run Heron on these machines
- 10.0.18.36 - heron01
- 10.0.18.37 - heron02
- 10.0.18.38 - heron03
and they have the user name ubuntu. You may need to change these appropriately for your setup.
Below figure shows the services and packages we'll install on each machine. In one machine we'll install ZooKeeper, Heron Binaries, Aurora Master, Mesos Master and HDFS master. In a large production deployment you may install some of these in different machines. In the rest of the machines we will install HDFS data node, Mesos slave and Aurora slave.
In this post we are going to explore the bare minimum configurations required for each service described above. For productions setups, it is recommended to configure these services for High availability. Also there are tons of configuration options available for performance tuning, log management, customizing the deployment locations.
Below figure shows the services and packages we'll install on each machine. In one machine we'll install ZooKeeper, Heron Binaries, Aurora Master, Mesos Master and HDFS master. In a large production deployment you may install some of these in different machines. In the rest of the machines we will install HDFS data node, Mesos slave and Aurora slave.
 |
| Heron Deployment |
In this post we are going to explore the bare minimum configurations required for each service described above. For productions setups, it is recommended to configure these services for High availability. Also there are tons of configuration options available for performance tuning, log management, customizing the deployment locations.
Correct IP addresses to Host matching
First step in setting up any cluster like this is to make sure the /etc/hosts file in each machine has the correct IP addresses and host names.
Here is my hosts file. Make sure to have the correct host file. Otherwise you'll get strange errors that are hard to debug.
sudo vi /etc/hosts 127.0.0.1 localhost 10.0.18.36 heron01 10.0.18.37 heron02 10.0.18.38 heron03
SSH Loging between nodes
To install a HDFS cluster, it is required to have passwordless SSH login between the machines. We can do this by generating a password less ssh key pair and placing the keys on all the machines. We need to add the public key to ~/.ssh/authorized_keys file in each machine as well. You can follow any of these guides to get this done. Guide1, Guide2.
Install JDK
Now, lets install JDK on all the nodes.sudo add-apt-repository ppa:webupd8team/java sudo apt-get update -y sudo apt-get install oracle-java8-installer -y sudo update-alternatives --config javaNow edit the .bashrc file to include Java
vi ~/.bashrc export JAVA_HOME=/usr/lib/jvm/java-8-oracle export PATH=/usr/lib/jvm/java-8-oracle/jre/bin:$PATHNow source the file.
source ~/.bashrc
Install Mesos
Lets install Mesos in each machine. You can use the same steps to install Mesos on each machine. Mesos scheduler and executor are both in the same Ubuntu package. So we can install the same package on each machine and run Mesos master and slaves on the appropriate machines. We are going to use heron01 as the master.
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv E56151BF
DISTRO=$(lsb_release -is | tr '[:upper:]' '[:lower:]')
CODENAME=$(lsb_release -cs)
echo "deb http://repos.mesosphere.io/${DISTRO} ${CODENAME} main" | \
sudo tee /etc/apt/sources.list.d/mesosphere.list
sudo apt-get -y update
# Use `apt-cache showpkg mesos | grep [version]` to find the exact version.
sudo apt-get -y install mesos=0.25.0-0.2.70.ubuntu1404
Now we can start Mesos master on the first node and Mesos slaves on the rest of the nodes.
In our setup we are keeping the node heron01 as the master and heron02 and heron03 as slaves. So these are the commands run on each machine.
By default the Mesos slave work directory is set to /tmp/mesos. So here is the configuration changes we did for Aurora Thermos.
You will only need to do the Heron related installations on the master node (heron01) or the node you are using to submit the topologies. So all the steps related to Heron are done in heron01 node in our case.
First lets install required dependencies on all nodes, so that we can run Heron on all the nodes.
Now lets download both client and tools packages.
By default Heron is installed on the ~/.heron folder. Here are the contents of this folder.
The heron-tracker needs to be configured to use the ZooKeeper state manager.
Okay we are at the end of our tutorial. If things doesn't go as smoothly as you would like, here are some debug tips.
In our setup we are keeping the node heron01 as the master and heron02 and heron03 as slaves. So these are the commands run on each machine.
Master (heron01)
sudo start mesos-master
Slaves (heron02 and heron03)
We need to configure the ZooKeeper location, so that slaves can discover the master.
sudo vi /etc/mesos/zk
In this setup zookeeper is running on heron01
zk://heron01:2181/mesos
Now start the mesos slave on the node
sudo start mesos-slave
Okay, we are done with Mesos. Lets install Aurora on these machines
Install Aurora
Unlike Mesos, Aurora Scheduler and Executor are installed from different packages. So we are going to install scheduler on the Meson master node and executor on the rest of the nodes.
Master (heron01)
wget -c https://apache.bintray.com/aurora/ubuntu-trusty/aurora-scheduler_0.12.0_amd64.deb sudo dpkg -i aurora-scheduler_0.12.0_amd64.deb
After this stop the scheduler and configure it
sudo stop aurora-scheduler sudo -u aurora mkdir -p /var/lib/aurora/scheduler/db sudo -u aurora mesos-log initialize --path=/var/lib/aurora/scheduler/dbChange the ZooKeeper URL in scheduler configuration
sudo vi /etc/default/aurora-scheduler # List of zookeeper endpoints ZK_ENDPOINTS="heron01:2181"
Now start the scheduler
sudo start aurora-scheduler
Slaves (heron02 & heron03)
sudo apt-get install -y python2.7 wget # NOTE: This appears to be a missing dependency of the mesos deb package and is needed # for the python mesos native bindings. sudo apt-get -y install libcurl4-nss-dev wget -c https://apache.bintray.com/aurora/ubuntu-trusty/aurora-executor_0.12.0_amd64.deb sudo dpkg -i aurora-executor_0.12.0_amd64.debMake sure Thermos configuration in the slaves points to the correct Mesos working directory.
By default the Mesos slave work directory is set to /tmp/mesos. So here is the configuration changes we did for Aurora Thermos.
sudo vi /etc/default/thermos MESOS_ROOT=/tmp/mesosThen add mesos-root configuration to the following file
sudo vi /etc/init/thermos
description "Aurora Thermos observer"
start on stopped rc RUNLEVEL=[2345]
respawn
post-stop exec sleep 5
pre-start exec mkdir -p /var/run/thermos
script
[ -r /etc/default/thermos ] && . /etc/default/thermos
exec start-stop-daemon --start --exec /usr/sbin/thermos_observer -- \
--port=${OBSERVER_PORT:-1338} \
--log_to_disk=DEBUG \
--log_dir=/home/ubuntu/aurora \
--mesos-root=${MESOS_ROOT:-/tmp/mesos} \
--log_to_stderr=google:INFO
end script
Install Aurora Client (heron01)
Heron uses Aurora client for submitting jobs. In our setup we will use the master node to submit the job. So lets install Aurora client on the master node.
wget -c https://apache.bintray.com/aurora/ubuntu-trusty/aurora-tools_0.12.0_amd64.deb sudo dpkg -i aurora-tools_0.12.0_amd64.deb
Now we are ready to install Heron on the master node.
Install Hadoop (All nodes)
Installing HDFS is not the main focus of this post. So we will briefly go through the steps to install a basic HDFS cluster on the three nodes.
We need to download the HDFS binary to all three machines. Then edit the following two files
core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://heron01:9000/</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.data.dir</name>
<value>/home/ubuntu/hadoop/dfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.name.dir</name>
<value>/home/ubuntu/hadoop/dfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
Change the JAVA_HOME in hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-8-oracle
Change the slaves file to include the hadoop workers.
heron02 heron03
Now start the HDFS in the master node (heron01) by using the command
./sbin/start-dfs.sh
These are very rough details on how to install a HDFS cluster. There are tons of detailed documentation available on deploying Hadoop and it is highly recommended to visit them.
Install Heron (heron01)
You will only need to do the Heron related installations on the master node (heron01) or the node you are using to submit the topologies. So all the steps related to Heron are done in heron01 node in our case.
First lets install required dependencies on all nodes, so that we can run Heron on all the nodes.
sudo apt-get install zip libunwind-setjmp0-dev zlib1g-dev unzip -yAll the following steps are done in the master node. If you choose to build Heron you can follow the Heron build instructions. Each Heron jobs is a self contained package that can be managed by a scheduler like Aurora or Yarn. So we are not required to install any Heron specific servers for managing the topologies. Heron comes with two packages. The heron-client-install contains all the required libraries (jar files, executable files and configurations) required for submitting a topology. The heron-tools package contains tools such as heron-tracker and UI to keep track of the topologies. The tools package is optional to use.
Now lets download both client and tools packages.
wget https://github.com/twitter/heron/releases/download/0.14.0/heron-client-install-0.14.0-ubuntu.sh wget https://github.com/twitter/heron/releases/download/0.14.0/heron-tools-install-0.14.0-ubuntu.shInstall Heron client and tools
chmod +x heron-client-install-0.14.0-ubuntu.sh chmod +x heron-tools-install-0.14.0-ubuntu.sh ./heron-client-install-0.14.0-ubuntu.sh --user ./heron-tools-install-0.14.0-ubuntu.sh --userMake sure we have the Heron binaries in the PATH. Add the ~/bin to your PATH.
export PATH=$PATH:/home/ubuntu/binNow lets configure Heron to use the Aurora Scheduler and ZooKeeper
By default Heron is installed on the ~/.heron folder. Here are the contents of this folder.
ubuntu@heron01:~$ ls -l ~/.heron total 28 drwxr-xr-x 2 ubuntu ubuntu 4096 Jan 1 1970 bin drwxr-xr-x 5 ubuntu ubuntu 4096 Jan 1 1970 conf drwxr-xr-x 2 ubuntu ubuntu 4096 Jan 1 1970 dist drwxr-xr-x 2 ubuntu ubuntu 4096 Jun 19 19:43 etc drwxr-xr-x 2 ubuntu ubuntu 4096 Jan 1 1970 examples drwxr-xr-x 7 ubuntu ubuntu 4096 Jan 1 1970 lib -rwxr-xr-x 1 ubuntu ubuntu 282 Jan 1 1970 release.yaml
The conf directory has configurations for various schedulers supported by Heron. In this case we are going to use Aurora scheduler.
The configurations we are going to change are in the file
The configurations we are going to change are in the file
conf/aurora/scheduler.yaml conf/aurora/uploader.yaml conf/aurora/statemgr.yaml conf/aurora/heron.auroraWe need to host the Heron core binary (which comes with the client package) in a shared location so that the scheduler can download it to execute the Heron topologies. In our case we are going to use HDFS as the shared location.
Copy the heron-core file to HDFS
Letsopy the heron core distribution to HDFS, so that it can be downloaded by the slaves. We are uploading the distrition to /heron/dist in HDFS. We need to configure this place in the scheduler configuration so that it can download it.hdfs fs -put ~/.heron/dist/heron-core.tar.gz /heron/dist
scheduler.yaml
This file contains the properties required by the scheduler. In our case we are using Aurora scheduler.# scheduler class for distributing the topology for execution heron.class.scheduler: com.twitter.heron.scheduler.aurora.AuroraScheduler # launcher class for submitting and launching the topology heron.class.launcher: com.twitter.heron.scheduler.aurora.AuroraLauncher # location of the core package heron.package.core.uri: /heron/dist/heron-core.tar.gz
# where to download a topology
heron.package.topology.uri: /home/ubuntu/.herondata/repository/topologies/${CLUSTER}/${ROLE}/${TOPOLOGY}
# location of java - pick it up from shell environment heron.directory.sandbox.java.home: /usr/lib/jvm/java-8-oracle # Invoke the IScheduler as a library directly heron.scheduler.is.service: FalseNote that we have configured the heron.package.core.uri to the HDFS location.
statemgr.yaml
This file contains the properties required to connect to the ZooKeeper#zookeeper state manager for managing state in a persistent fashion heron.class.state.manager: com.twitter.heron.statemgr.zookeeper.curator.CuratorStateManager # zookeeper state manager connection string heron.statemgr.connection.string: "heron01:2181" # path of the root address to store the state in a local file system heron.statemgr.root.path: "/heron" # create the zookeeper nodes, if they do not exist heron.statemgr.zookeeper.is.initialize.tree: True # timeout in ms to wait before considering zookeeper session is dead heron.statemgr.zookeeper.session.timeout.ms: 30000 # timeout in ms to wait before considering zookeeper connection is dead heron.statemgr.zookeeper.connection.timeout.ms: 30000 # timeout in ms to wait before considering zookeeper connection is dead heron.statemgr.zookeeper.retry.count: 10 # duration of time to wait until the next retry heron.statemgr.zookeeper.retry.interval.ms: 10000
uploader.yaml
Details about the HDFS file uploader.# uploader class for transferring the topology jar/tar files to storage
heron.class.uploader: com.twitter.heron.uploader.hdfs.HdfsUploader
# Directory of config files for local hadoop client to read from
heron.uploader.hdfs.config.directory: /home/ubuntu/hadoop-2.7.2/etc/hadoop
# The URI of the directory for uploading topologies in the hdfs uploader
heron.uploader.hdfs.topologies.directory.uri: /heron/topologies/${CLUSTER}/${ROLE}/${TOPOLOGY}
Note that we have configured the topology upload directory. The same location is in the scheduler.yaml as well to download the topology.heron.aurora
This is the aurora script used by heron to execute the job on the Mesos sandboxes. The default file uses heron local file system and curl to download the files. We need to change this to use Hadoop command to download the files.
Here are the two changes we made.
fetch_heron_system = Process( name = 'fetch_heron_system', cmdline = '/home/ubuntu/hadoop-2.7.2/bin/hdfs dfs -get %s %s && tar zxf %s' % (heron_core_release_uri, core_release_file, core_release_file) ) fetch_user_package = Process( name = 'fetch_user_package', cmdline = '/home/ubuntu/hadoop-2.7.2/bin/hdfs dfs -get %s %s && tar zxf %s' % (heron_topology_jar_uri, topology_package_file, topology_package_file) )
Submitting a topology
After a long set of installations and configurations we are finally ready to submit a Heron topology to the Aurora cluster.
There is one small thing we need to take care before we can submit the topology. We need to make sure the Aurora client configuration has the same client name as the configuration directory of aurora of aurora scheduler. (i.e last part of ~/.heron/conf/aurora).
There is one small thing we need to take care before we can submit the topology. We need to make sure the Aurora client configuration has the same client name as the configuration directory of aurora of aurora scheduler. (i.e last part of ~/.heron/conf/aurora).
sudo vi /etc/aurora/clusters.json
[
{
"auth_mechanism": "UNAUTHENTICATED",
"name": "aurora",
"scheduler_zk_path": "/aurora/scheduler",
"slave_root": "/var/lib/mesos",
"slave_run_directory": "latest",
"zk": "127.0.1.1"
}
]
Submit Topology
Here is a command to submit an example topology included with Heron.
heron submit aurora/ubuntu/devel --config-path ~/.heron/conf/ ~/.heron/examples/heron-examples.jar com.twitter.heron.examples.ExclamationTopology ExclamationTopology
Kill Topology
Here is a command to kill the above topology.
heron kill aurora/ubuntu/devel ExclamationTopology
Heron Tracker & UI
You can run Heron tracker and ui to see the topology in the browser.The heron-tracker needs to be configured to use the ZooKeeper state manager.
vi .herontools/conf/heron_tracker.yamlEdit the file to point to ZooKeeper.
statemgrs:
-
type: "zookeeper"
name: "localzk"
hostport: "heron01:2181"
rootpath: "heron"
tunnelhost: "localhost"
In the master node run the following commands in two separate terminalsheron-tracker heron-ui
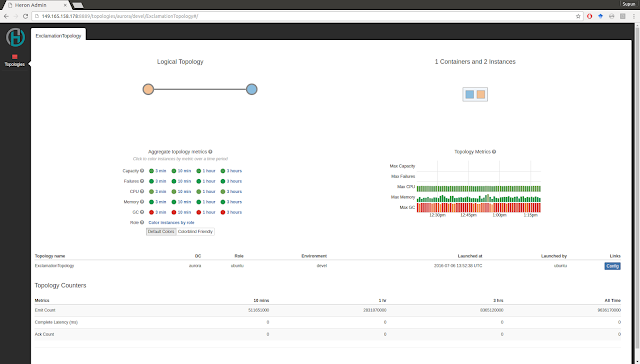
Here is an example of the Heron UI

Okay we are at the end of our tutorial. If things doesn't go as smoothly as you would like, here are some debug tips.
- Mesos and Aurora has UIs and they give some valuable information when trying to figure out what went wrong
- The Heron logs are in the Mesos sandboxes created for submitting the topology. You can look for these for specific errors.
Feel free to conact Heron users group, for any questions you may have.

